
Tamas Koncz



My inspiration to write this post was Julia Silge’s “She giggles, he gallops” on pudding.cool.
Julia examines 2,000 film scripts, to uncover certain “gender bias” - notably, she compared what are the most frequent words following “he” and “she” in the scripts.
I’m going to apply the same idea to the subtitle data of the TV series ‘The Big Bang Theory’.
Just before we dive in - this post is the second in my “TBBT (Tidy)Text analysis” mini-series, if interested, you can find the first one here, in which I look at the relation between average IMDB scores of episodes and dominating character “mentions”.
And now, let’s get rolling!
Data-wise, our starting point is the same as in the first post:
| episode_id | episode_full_text |
|---|---|
| s1e1 | So if a photon is directed through a plane with two slits in it and either slit is observed, it will not go through both slit… |
| s1e2 | Here we go. Pad thai, no peanuts. But does it have peanut oil? I’m not sure. Everyone keep an eye on Howard in case he starts… |
| s1e3 | Alright, just a few more feet. And… here we are, gentlemen, the Gates of Elzebob. Good Lord. Don’t panic. This is what the … |
The approach I’m taking is simple: look at all two-word pairs, where the first world defines the gender. The second word is what we are going to analyze.
First, we need to slice the text into bigrams:
bigrams <- full_episode_text %>%
unnest_tokens(output = bigram,
input = episode_full_text,
token = "ngrams",
n = 2)| episode_id | bigram |
|---|---|
| s1e1 | so if |
| s1e1 | if a |
| s1e1 | a photon |
| s1e1 | photon is |
I’ll cross reference this bigrams list with a gender “lexicon” I have defined earlier, which apart from the usual “he/she”, also contains the names of the important characters from the show (only first 6 lines shown below - for full list, please refer to my github):
| gender | word | possesive |
|---|---|---|
| male | he | his |
| female | she | her |
| male | howard | howard’s |
| female | penny | penny’s |
| male | leonard | leonard’s |
| male | sheldon | sheldon’s |
Let’s use this lexicon as a filter (via simple regex), and create separte columns for the two words of the bigrams as well:
gender_bigrams <- bigrams %>%
filter(str_detect(bigram, gender_words_regex)) %>%
mutate(gender_word = str_split(bigram, pattern = " ", n = 2, simplify = TRUE)[,1],
word = str_split(bigram, pattern = " ", n = 2, simplify = TRUE)[,2]) %>%
inner_join(gender_word_lexicon, by = c("gender_word" = "word")) %>%
select(gender, word)What I am going to do exactly with these word pairs?
My original idea was to run a tf-idf analysis, to “cluster” the most typical words for each gender.
However, when I first ran a trial, I noticed something interesting: many words in the “she” category were sensual ones (“feel”, “kissed”, “smiled”…), while for “he” most words were pretty general (“talk”, “sit”, “boy”…).
This (and the sad fact that most of the words appeared only once or twice, making it hard to do meaningful tf-idf in their raw format) made me pivot somewhat from my starting idea - and I decided to group words by sentiments, and compare those for the two genders.
For this, I’m using the NRC lexicon, which is built-in accessible in the tidytext R package.
sentiments_nrc <- get_sentiments(lexicon = "nrc")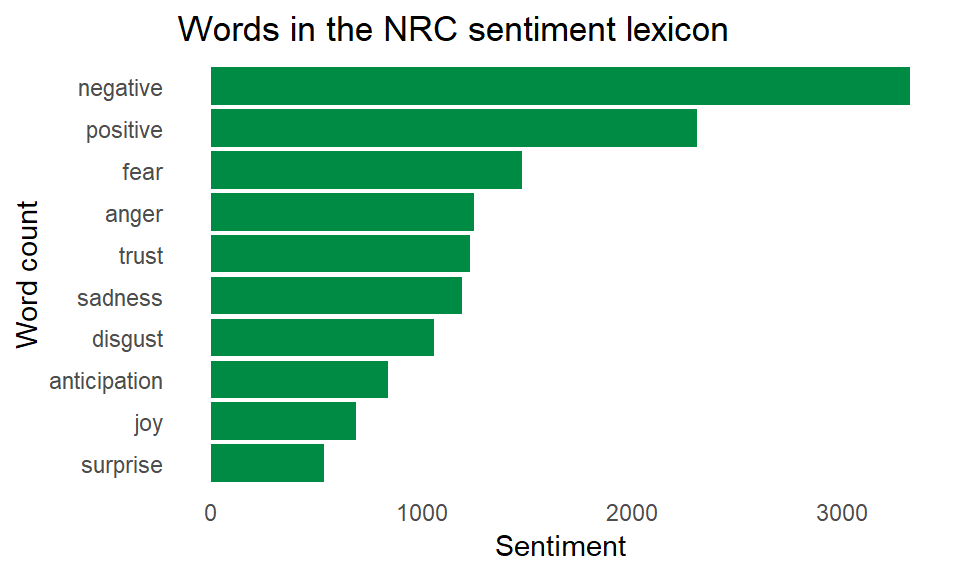 A glimpse into the sentiment lexicon’s categories… The lexicon does not contain all English words, but should be more than enough for a light analysis of subtitles.
A glimpse into the sentiment lexicon’s categories… The lexicon does not contain all English words, but should be more than enough for a light analysis of subtitles.
gender_bigrams_w_nrc <- gender_bigrams %>%
inner_join(sentiments_nrc, by = "word")In a short step we match up the sentiments with the bigram collection (above), and the results are ready to be visualized1:
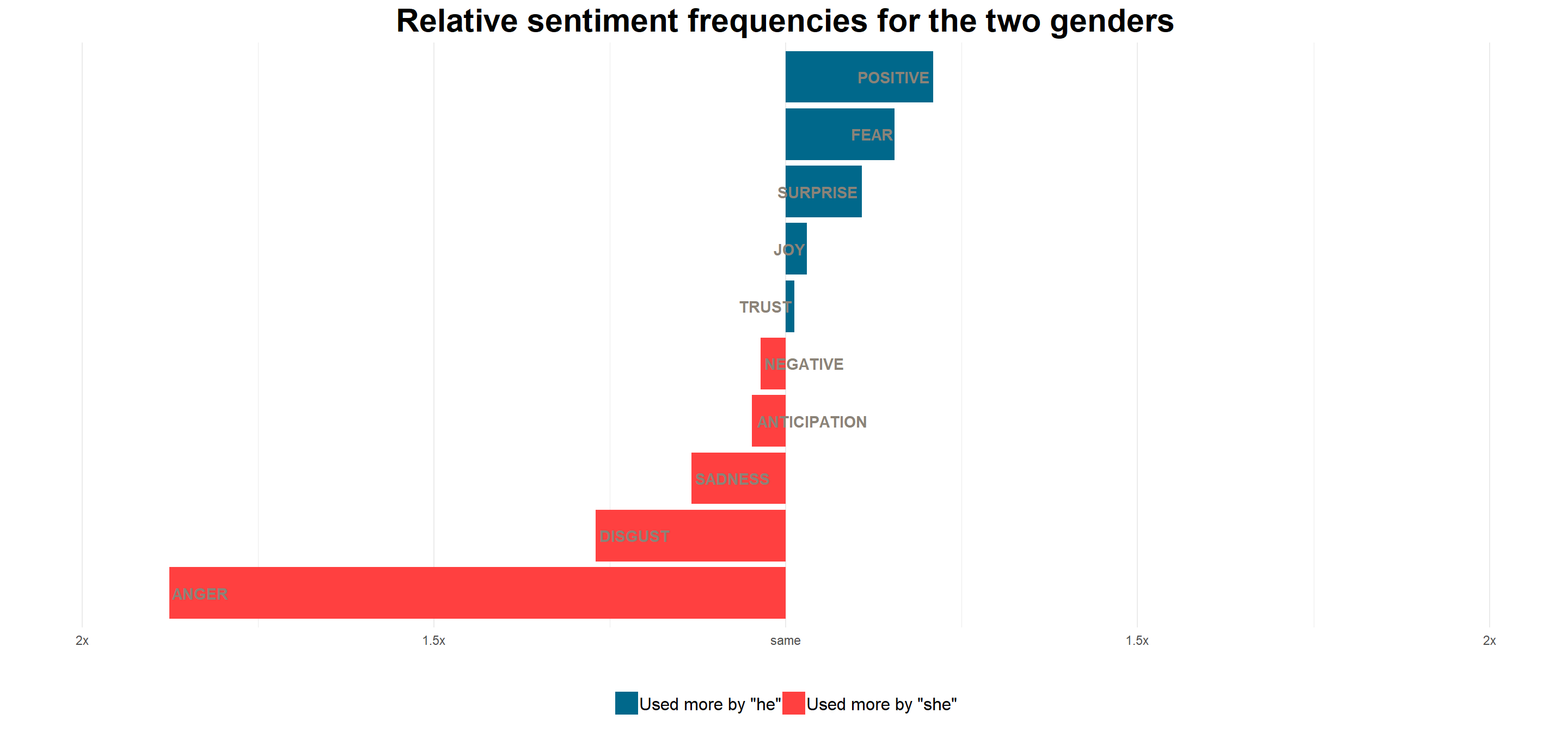
There is a high likelihood that “she” will be angry in the context mentioned - while “he” is mostly in the positive.
Probably more interestingly, men are also a lot less likely to “exhibit” any sentiments - maybe their feelings are less talked about?(!)
None of this should be a starting point for deep conversations about gender roles in Hollywood - if you are looking for that, please head over to Julia’s post I linked in the beginning.
However, if you were looking for some ideas about what’s in subtitles for some data analysis, I hope I could gave would you a nice glimpse.
Footnotes:
Methodology used: first, I calculated the ratio of each sentiment group within genders (~= words belonging to the sentiment group / total words for gender). Then, I checked these within-gender frequencies across the two genders, which gave me the ratios - from here, I only had to tidy it up for visualization.↩